Salesforce에서 다수의 파일을 수동으로 관리하는 비효율을 해결하기 위해, Apex의 Compression 네임스페이스(Apex Zip library)를 활용한 파일 압축 및 해제는 필수적입니다. 이 기능을 사용하면 여러 파일을 하나의 Zip 파일로 묶거나, 압축 파일을 자동으로 풀어 개별 파일로 저장하는 등 복잡한 파일 관리 업무를 자동화할 수 있습니다. 이 글에서는 압축 파일 생성(Zipping)부터 해제(Unzipping)까지의 모든 과정, 실무 코드 예제, 그리고 반드시 숙지해야 할 거버너 제한까지 완벽하게 다룹니다.

1. 도입: Salesforce 데이터 관리, 압축 파일이 왜 필수일까요?
Salesforce 환경에서 업무를 하다 보면 여러 파일을 한 번에 처리해야 하는 상황을 자주 마주하게 됩니다. 예를 들어, 한 고객(Account) 레코드에 첨부된 10개의 견적서와 5개의 계약서를 이메일로 한 번에 보내야 한다면 어떻게 하시겠습니까? 파일을 하나씩 다운로드해서 다시 첨부하는 작업은 번거롭고 귀중한 시간을 낭비하게 만듭니다. 이러한 비효율은 데이터 마이그레이션이나 백업 시 더 큰 문제로 다가옵니다. 수백, 수천 개의 파일을 개별적으로 다루는 것은 상상만 해도 끔찍한 일입니다.
이처럼 복잡하고 반복적인 파일 관리 문제에 대한 가장 효율적인 해결책은 바로 salesforce apex 코드 내에서 압축 파일을 활용하는 것입니다. Salesforce는 Compression 네임스페이스, 흔히 Apex Zip library라고 불리는 강력한 기능을 제공합니다. 이를 통해 개발자는 Apex 코드로 여러 파일을 하나의 압축 파일(Zip)으로 손쉽게 묶거나, 외부에서 받은 압축 파일을 자동으로 풀어 개별 파일로 처리할 수 있습니다. 이 기능은 단순한 편의를 넘어 업무 자동화와 디지털 트랜스포메이션의 핵심 요소로 작용합니다.
이 글 하나만으로 여러분은 salesforce apex를 활용한 압축 파일 생성(Zipping)부터 압축 해제(Unzipping)까지의 모든 과정을 마스터하게 될 것입니다. 실무에 바로 적용할 수 있는 코드 예제와 반드시 알아야 할 핵심 유의사항까지, 압축 파일 처리에 필요한 모든 지식을 명확하고 깊이 있게 알려드립니다.
2. 핵심 개념 이해: Apex의 숨은 보석, Compression 네임스페이스 파헤치기
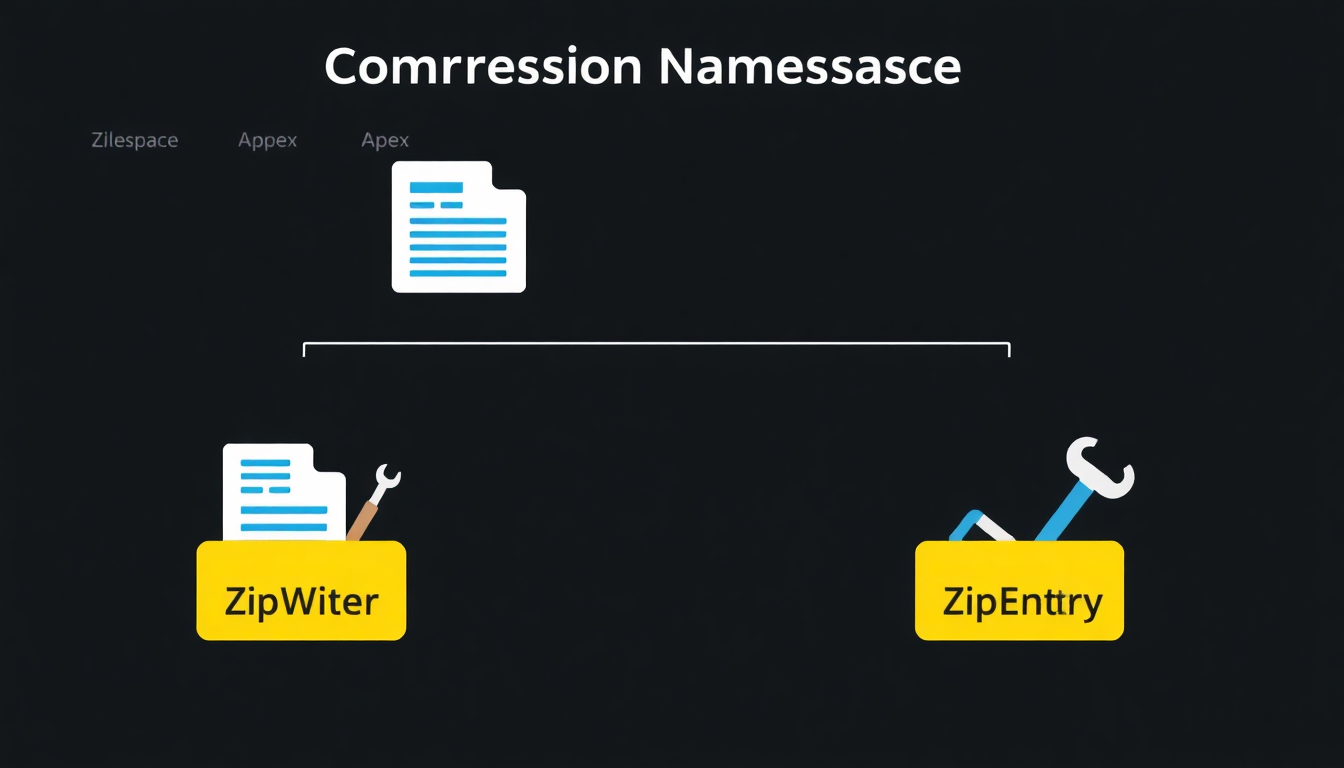
많은 개발자들이 ‘Apex Zip library’라고 부르는 기능의 공식 명칭은 바로 Compression 네임스페이스입니다. 이 네임스페이스는 Salesforce 플랫폼 내에서 파일 압축 및 해제와 관련된 모든 기능을 담당하는 핵심적인 도구 상자입니다. 복잡한 외부 라이브러리 없이도 Salesforce가 기본으로 제공하는 기능을 통해 안정적이고 효율적인 파일 처리가 가능해졌습니다. 압축 파일을 다루기 위해 우리는 이 안에 있는 세 가지 핵심 클래스를 반드시 이해해야 합니다.
이 클래스들은 각각 명확한 역할을 가지고 있으며, 서로 유기적으로 동작하여 압축 및 해제 프로세스를 완성합니다. 각 클래스의 역할을 정확히 인지하면 코드를 작성하고 이해하는 것이 훨씬 수월해집니다.
주요 클래스 상세 소개
| 클래스명 | 역할 | 비유 |
|---|---|---|
Compression.ZipWriter |
여러 개의 개별 파일(Blob 데이터)을 입력받아 하나의 압축 파일(Zip Archive Blob)을 생성합니다. | 파일을 차곡차곡 담아 하나의 압축 가방을 만드는 도구 |
Compression.ZipReader |
ZipWriter와 반대로, 압축된 파일(Zip Archive Blob)을 읽어 그 안에 포함된 개별 파일들을 추출합니다. |
압축 가방을 열어 내용물을 하나씩 꺼내는 도구 |
Compression.ZipEntry |
압축 파일 내에 포함된 개별 파일 또는 폴더 하나하나를 의미하는 객체입니다. 이 객체를 통해 각 파일의 이름(getName())과 실제 파일 데이터(getBlob())에 접근할 수 있습니다. |
압축 가방 속에 들어있는 각각의 내용물 |
결국 Compression.ZipEntry 객체는 압축 파일 속 각각의 내용물을 대표하는 가장 중요한 단위입니다. 압축을 할 때는 각 파일을 ZipEntry로 변환하여 ZipWriter에 추가하는 과정이며, 압축을 풀 때는 ZipReader를 통해 ZipEntry 목록을 얻고 각 ZipEntry에서 파일 데이터(Blob)를 추출하는 과정이라고 이해하면 됩니다.
3. 실전 예제 1: salesforce apex로 여러 파일을 하나의 Zip 파일로 압축하기 (Zipping)
이제 실제 코드를 통해 특정 레코드에 첨부된 모든 파일을 하나의 Zip 파일로 압축하는 방법을 단계별로 알아보겠습니다. 가장 흔한 시나리오인 ‘계정(Account)에 첨부된 모든 파일을 압축하여 새로운 파일로 저장하기’를 예제로 사용하겠습니다. 이 코드를 이해하면 어떤 객체에 연결된 파일이든 동일한 로직으로 압축할 수 있습니다.
이 프로세스는 단순히 파일을 묶는 것을 넘어, 여러 문서를 하나의 패키지로 만들어 이메일로 전송하거나 외부 시스템으로 전달하는 등 다양한 업무 자동화의 첫걸음이 될 수 있습니다.
단계별 로직 설명
1. ZipWriter 인스턴스 생성: 압축 작업을 시작하기 위해 가장 먼저 Compression.ZipWriter 객체를 생성합니다. 이 객체가 압축 파일의 기반이 됩니다.
2. 압축할 파일 데이터 준비: SOQL 쿼리를 사용하여 압축하고자 하는 파일들을 가져옵니다. 예제에서는 특정 AccountId에 연결된 ContentVersion 레코드들을 조회하여 파일명(PathOnClient)과 파일의 실제 데이터(VersionData)를 준비합니다.
3. 파일을 Zip에 추가: 반복문(for-loop)을 사용하여 조회된 각 ContentVersion 레코드를 ZipWriter에 추가합니다. writer.addEntry(파일명, 파일데이터); 메소드가 호출될 때마다, 해당 파일은 하나의 Compression.ZipEntry 형태로 압축 파일 내에 기록됩니다.
4. 최종 압축 파일 생성: 모든 파일을 ZipWriter에 추가했다면, writer.getArchive() 메소드를 호출하여 최종 결과물인 압축 파일을 Blob 데이터 형태로 얻습니다.
5. 결과물 활용: 생성된 Zip Blob은 그 자체로 활용할 수 있습니다. 새로운 ContentVersion 레코드를 만들어 Salesforce Files에 다시 저장하거나, Messaging.EmailFileAttachment 객체를 생성하여 이메일 첨부파일로 발송할 수 있습니다.
전체 코드 예제
// Salesforce Apex: 특정 계정에 첨부된 모든 파일을 하나의 Zip으로 압축하여 저장하는 예제
public static void createZipFileFromAttachments(Id accountId) {
// 1. 압축 작업을 위한 ZipWriter 인스턴스 생성
Compression.ZipWriter writer = new Compression.ZipWriter();
// 2. 계정에 연결된 ContentDocument들의 ID를 조회
List<ContentDocumentLink> cdls = [SELECT ContentDocumentId FROM ContentDocumentLink WHERE LinkedEntityId = :accountId];
Set<Id> contentDocumentIds = new Set<Id>();
for (ContentDocumentLink cdl : cdls) {
contentDocumentIds.add(cdl.ContentDocumentId);
}
// 3. 최신 버전의 파일 데이터(ContentVersion)를 조회
if (!contentDocumentIds.isEmpty()) {
for (ContentVersion cv : [SELECT PathOnClient, VersionData FROM ContentVersion WHERE ContentDocumentId IN :contentDocumentIds AND IsLatest = true]) {
// 4. 각 파일을 ZipWriter에 추가 (이것이 하나의 Compression.ZipEntry가 됨)
writer.addEntry(cv.PathOnClient, cv.VersionData);
}
}
// 5. 최종 압축 파일을 Blob 형태로 얻기
Blob zipBlob = writer.getArchive();
// 6. 생성된 Zip 파일을 Salesforce Files로 저장
ContentVersion zipCv = new ContentVersion();
zipCv.Title = 'Archived_Attachments.zip';
zipCv.PathOnClient = 'Archived_Attachments.zip';
zipCv.VersionData = zipBlob;
insert zipCv;
// 7. 저장된 파일을 다시 계정에 연결
ContentDocumentLink cdlToInsert = new ContentDocumentLink();
cdlToInsert.ContentDocumentId = [SELECT ContentDocumentId FROM ContentVersion WHERE Id = :zipCv.Id].ContentDocumentId;
cdlToInsert.LinkedEntityId = accountId;
cdlToInsert.ShareType = 'V'; // Viewer permission
insert cdlToInsert;
}
이 코드는 Salesforce 개발자 공식 문서에서 권장하는 표준적인 압축 파일 생성 방식을 따르고 있으며, ContentVersion 객체를 다루는 가장 효율적인 방법입니다. 이 패턴을 활용하면 대량의 파일을 체계적으로 관리하고 백업하는 로직을 손쉽게 구현할 수 있습니다.
4. 실전 예제 2: salesforce apex로 Zip 파일 압축 풀고 개별 파일로 저장하기 (Unzipping)
이번에는 반대로, 압축 파일을 받아 그 내용물을 개별 파일로 저장하는 방법을 알아보겠습니다. 외부 시스템에서 API를 통해 Zip 파일을 받거나, 이메일로 수신된 Zip 첨부파일의 압축을 자동으로 풀어 내부 파일들을 각각 Salesforce Files로 저장하는 자동화 시나리오를 코드로 구현해 보겠습니다.
이러한 압축 해제 자동화는 수동 파일 업로드 업무를 획기적으로 줄여주며, 데이터 수신 프로세스의 정확성과 속도를 크게 향상시킬 수 있습니다. 특히 이메일 자동화와 연계한 압축 해제 로직은 InboundEmailHandler 인터페이스와 함께 사용될 때 강력한 시너지를 발휘합니다.
단계별 로직 설명
1. 압축 해제할 Blob 준비: 작업의 대상이 되는 Zip 파일의 Blob 데이터를 준비합니다. 이 데이터는 이메일 첨부파일, API 요청 본문 등 다양한 소스로부터 얻을 수 있습니다.
2. ZipReader 인스턴스 생성: 준비된 Blob 데이터를 인자로 전달하여 Compression.ZipReader 객체를 생성합니다. 이 객체를 통해 압축 파일의 내용물을 읽을 수 있습니다.
3. 내부 엔트리 목록 가져오기: reader.getEntries() 메소드를 호출하여 Zip 파일 내부에 있는 모든 Compression.ZipEntry 객체의 리스트를 가져옵니다. 이 리스트는 압축 파일에 포함된 모든 파일의 목록입니다.
4. 개별 파일 추출 및 처리: 반복문(for-loop)을 사용하여 ZipEntry 리스트를 순회하며 각 엔트리에 접근합니다. 각 Compression.ZipEntry 객체에서 entry.getName() 메소드로 파일명을, entry.getBlob() 메소드로 파일의 실제 데이터를 추출합니다.
5. 추출된 파일 저장: 추출된 파일명과 데이터를 사용하여 새로운 ContentVersion 레코드를 생성하고, 리스트에 담아두었다가 반복문이 끝난 후 한 번의 DML(insert)로 데이터베이스에 저장하여 시스템 부하를 최소화합니다.
전체 코드 예제
// Salesforce Apex: 이메일로 받은 Zip 파일의 압축을 풀어 개별 파일로 저장하는 예제
public static void unzipAndSaveFiles(Blob zipBlob, Id relatedRecordId) {
// 1. Zip Blob으로 ZipReader 인스턴스 생성
Compression.ZipReader reader = new Compression.ZipReader(zipBlob);
// 2. Zip 파일 내의 모든 엔트리(파일) 목록을 가져옴
List<Compression.ZipEntry> entries = reader.getEntries();
System.debug('Number of entries in zip: ' + entries.size());
List<ContentVersion> filesToInsert = new List<ContentVersion>();
// 3. 각 엔트리를 순회하며 개별 파일 처리
for (Compression.ZipEntry entry : entries) {
String fileName = entry.getName();
Blob fileData = entry.getBlob();
// 4. 추출된 파일 데이터로 ContentVersion 레코드 생성 준비
ContentVersion cv = new ContentVersion();
cv.Title = fileName;
cv.PathOnClient = fileName;
cv.VersionData = fileData;
filesToInsert.add(cv);
}
// 5. 준비된 파일들을 한 번에 DB에 삽입 (DML 최적화)
if (!filesToInsert.isEmpty()) {
insert filesToInsert;
// 6. (선택사항) 저장된 파일들을 특정 레코드에 연결
List<ContentDocumentLink> cdlsToInsert = new List<ContentDocumentLink>();
for(ContentVersion insertedCv : [SELECT Id, ContentDocumentId FROM ContentVersion WHERE Id IN :filesToInsert]) {
ContentDocumentLink cdl = new ContentDocumentLink();
cdl.ContentDocumentId = insertedCv.ContentDocumentId;
cdl.LinkedEntityId = relatedRecordId;
cdl.ShareType = 'V';
cdlsToInsert.add(cdl);
}
insert cdlsToInsert;
}
}
5. 실무 적용 전 반드시 알아야 할 제한사항 (Governor Limits)
Compression 네임스페이스는 매우 강력한 도구이지만, Salesforce 멀티 테넌트 아키텍처의 안정성을 위해 모든 salesforce apex 트랜잭션에 적용되는 거버너 제한(Governor Limits) 내에서 동작한다는 점을 반드시 인지해야 합니다. 파일 처리는 특히 CPU와 메모리 자원을 많이 사용할 수 있으므로, 관련 제한사항을 미리 숙지하고 코드를 설계하는 것이 매우 중요합니다. 이를 무시하면 예기치 않은 오류가 발생하여 프로덕션 환경에 영향을 줄 수 있습니다.
Salesforce는 플랫폼의 안정적인 운영을 위해 모든 Apex 트랜잭션에 거버너 제한을 적용합니다. 파일 처리 시에는 특히 CPU 시간과 힙 크기 제한을 주의 깊게 모니터링해야 하며, 대용량 처리가 예상될 경우 반드시 비동기 방식을 채택해야 합니다.
주요 고려사항 및 해결책
| 제한사항 | 설명 | 해결책 |
|---|---|---|
| CPU Time Limit | 매우 크거나 많은 수의 파일을 압축/해제하는 작업은 상당한 CPU 처리 시간을 소모합니다. 동기(Synchronous) 트랜잭션에서는 최대 10초, 비동기(Asynchronous)에서는 60초의 제한이 있습니다. 이 시간을 초과하면 CPU time limit exceeded 오류가 발생합니다. |
대용량 파일 처리는 반드시 비동기 처리(@future, Queueable, Batch Apex)를 사용하여 별도의 트랜잭션에서 실행해야 합니다. 이를 통해 더 높은 제한을 적용받고 현재 트랜잭션에 영향을 주지 않을 수 있습니다. |
| Heap Size Limit | 압축하거나 해제할 파일의 Blob 데이터는 처리 과정에서 메모리(힙)에 적재됩니다. 동기 Apex는 6MB, 비동기 Apex는 12MB의 힙 크기 제한이 있습니다. 처리하려는 파일들의 총 크기가 이 제한을 초과하면 Apex heap size too large 오류가 발생합니다. |
한 번에 너무 많은 파일을 처리하지 않도록 로직을 설계해야 합니다. 예를 들어, 100개의 파일을 처리해야 한다면 20개씩 5번의 트랜잭션으로 나누어 처리하는 분할 처리 전략이 필요합니다. |
| Blob Size Limit | getArchive() 메소드로 생성되는 최종 압축 파일(Blob)의 크기 또한 힙 크기 제한의 영향을 받습니다. 압축 전 원본 파일들의 총합뿐만 아니라, 압축 후 결과물의 크기도 힙 제한 내에 있어야 합니다. |
최종 압축 파일의 예상 크기가 힙 제한에 근접할 경우, 여러 개의 압축 파일로 나누어 생성하는 방법을 고려해야 합니다. |
6. 마무리: 이제 당신도 Apex 파일 처리 전문가입니다.
오늘 우리는 Apex Zip library, 즉 Compression 네임스페이스를 사용하여 salesforce apex 환경에서 파일을 효과적으로 압축하고 해제하는 방법을 깊이 있게 학습했습니다. ZipWriter와 ZipReader를 통해 압축 파일을 자유자재로 생성하고 읽을 수 있으며, 그 과정의 중심에는 압축 파일 내 개별 파일을 다루는 핵심 열쇠인 Compression.ZipEntry 객체가 있음을 확인했습니다. 또한, 강력한 기능에는 책임이 따르듯, 거버너 제한을 이해하고 비동기 처리와 같은 해결책을 적용하는 것의 중요성도 깨달았습니다.
이 글에서 다룬 개념과 코드 예제는 여러분이 Salesforce 개발자로서 파일 처리 자동화의 새로운 가능성을 여는 데 훌륭한 출발점이 될 것입니다. 반복적인 수동 작업을 코드로 자동화하여 생산성을 높이고, 사용자가 더 편리하게 데이터를 다룰 수 있는 환경을 만들어보세요.
행동 유도 (Call to Action):
- 지금 바로 여러분의 개발자 Sandbox에 접속해서 오늘 배운 코드 예제를 직접 실행해보세요! 특정 계정에 테스트 파일을 몇 개 첨부하고 압축하는 코드를 실행하며 동작 원리를 몸소 체험해보는 것이 가장 좋은 학습 방법입니다.
- 실무에서 압축 파일 처리를 자동화하여 해결하고 싶은 재미있는 아이디어가 있다면 댓글로 공유해주세요. 다른 개발자들과 함께 고민하며 더 나은 해결책을 찾아봅시다.